Evaluation is all you need: think like a scientist when building AI
You can’t land a plane if your altimeter is off by 50 feet. You can't paint a masterpiece if you can’t see. You can’t build an AI pipeline if you can’t evaluate accuracy.
LLMs have made building with AI incredibly easy and yet still very few companies have incorporated AI into their product. It’s not enough to build a feature, that feature needs to be good. If your goal is to build good AI software, you need to switch from thinking like an engineer to thinking like a scientist.
Engineers design systems and then build them. Scientists run experiments based on a hypothesis until they have something that works. Thinking like a scientist starts by setting a clear goal and a framework for how you will evaluate experiments and measure success.
Every ML engineer worth their salt knows the importance of evaluation. Now that anyone can be an AI engineer, every builder needs to understand why evaluation is so important and how to build measurable AI pipelines and robust evaluations.
Why probabilistic software requires a mindset shift
Testing is critical to all forms of software development. Engineers are used to writing unit and integration tests. Before the product is shipped it has to undergo a round of QA testing to make sure nothing fell through the cracks. Deterministic software requires deterministic tests: either the test passes or it doesn’t. When a test doesn’t pass it implies a bug in the code and necessitates a fix.
In deterministic software, the building process is
The uncertainty in this type of software comes post-launch: how will your users receive the feature and what will the effect on metrics be? However, whether the software itself works isn’t uncertain.
Probabilistic software is products where what the user sees or experiences isn’t known in advance. A news feed, a search page, a chatbot, and an agent are all examples of probabilistic software. When I talk about building probabilistic software, I’m not just talking about training models, I also mean any products that use the outputs of ML models in the experience.
Building these types of products requires a new way of thinking about testing and development. The correctness of code is not black and white. You can’t whiteboard out the “right” solution to a problem because there is no right solution, only one that is better than the previous one. We go from the discrete labels of correct/incorrect to a continuous measure of quality.
This difference translates into the software development process. Instead of the linear path from designing to launching, probabilistic software requires the iterative approach of a scientist.
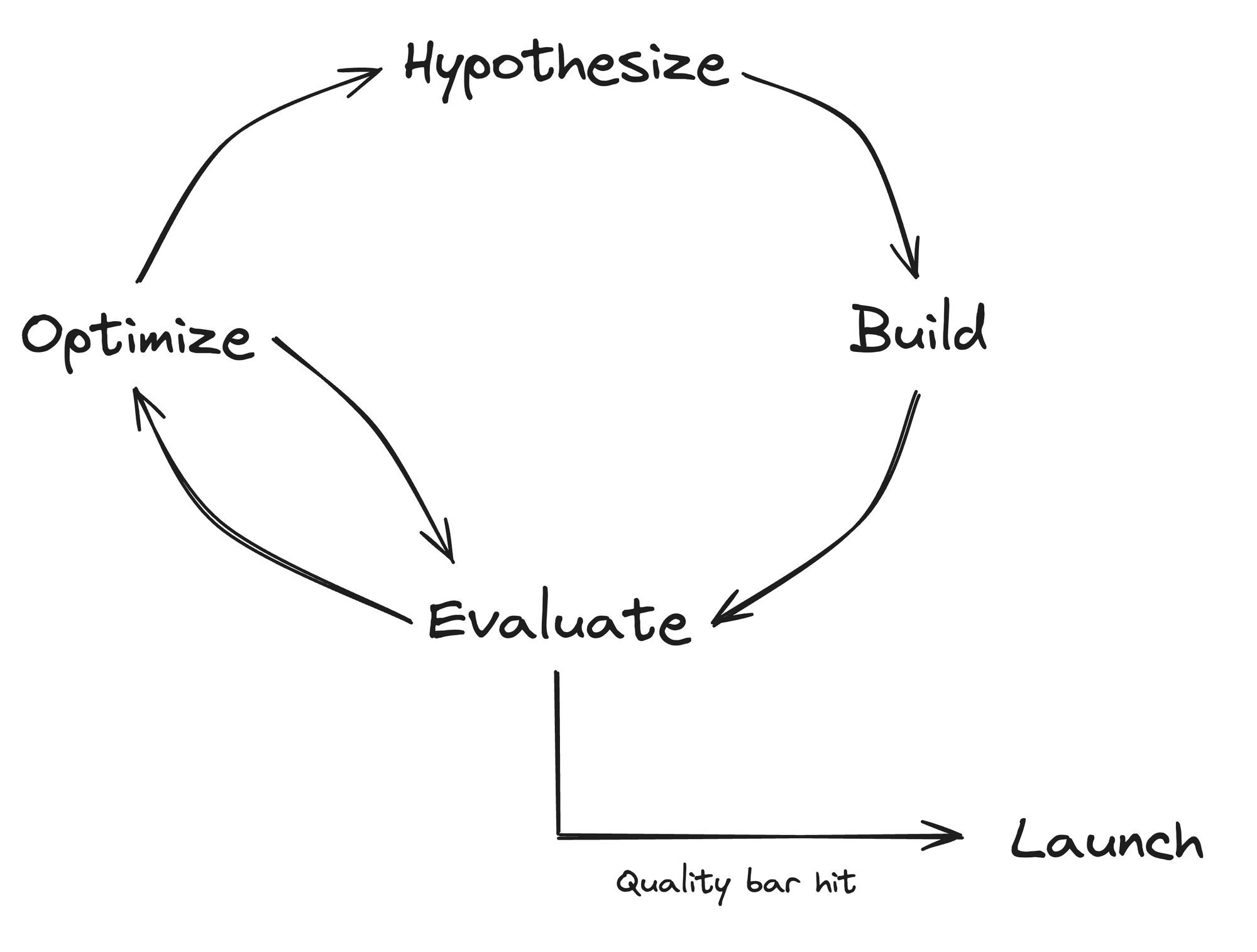
- Hypothesize - you’ll usually have some idea of what you think will work. You learn from past experiments and prior art.
- Build - you build out a version to test your hypothesis.
- Evaluate - you evaluate your solution on some quality metric. I know this sounds hand-wavy
- Optimize - try out a bunch of different approaches and hyperparameters. This feeds back into your evaluation function.
- …repeat
- Launch - once you’ve reached a sufficient quality bar, you are ready to launch.
When you’re building AI software, you need to keep trying and iterating until you reach a sufficient quality bar. One of the main thing that differentiates deterministic engineering from probabilistic engineering is that in the world of AI, throwing stuff at the wall and seeing what sticks is often a pretty good strategy, especially in the world of deep learning.
Code is not the only input into probabilistic software: data is too. The quality and amount of data is often the most important factor in improving ML systems. That’s a topic for another day.
The lynchpin of this entire process is evaluation. Unless you have a well-defined, rigorous method for evaluation, you’ll never be able to build good AI software.
What does evaluation mean?
Evals are the tools you use to measure and compare things. Evals can be relative (response A is better than response B) or absolute (this output was correct or incorrect). The important thing is the evals help you measure the quality of what you’re building in a concrete and well-defined way.
I used to be the quality and ranking PM on Google Discover. Discover is the article recommendations in the Google app and pretty much the only thing that matters is the quality of the recommendations.
The key question is what exactly does “quality” mean and how do we improve it?
First, let’s talk about our goal. As with most consumer products, our goal was to increase growth and retention. However, these are lagging indicators that take weeks or months to measure. It’s logical to assume that when people click on content they are more likely to retain over time. So one measure of quality might just be CTR (click-through rate). In fact, CTR is exactly what our model was trained to predict.
However, anyone who has read Buzzfeed knows that clicking on something is not indicative of quality. If you only optimize for CTR, you’ll end up with a lot of clickbait and salacious gossip. Clearly, there’s something else that makes up “quality” that can’t just be measured by historical user actions. We need metrics that can capture the nuance of “better”.
On Google Search, we used side-by-side evals to capture this nuance with extremely detailed instructions to search raters on what constituted “better”. For example, if we were trying to limit clickbait we’d write out a very specific definition of clickbait and have raters mark two different feeds on the amount of clickbait they contained. Through this process of breaking down quality into measurable, well-defined, repeatable aspects, we were able to drastically and rapidly improve. When you’re building probabilistic products for other people you can’t just “eyeball” results, you need a process to measure progress.
What makes a good eval?
The type of eval depends on the type of content being evaluated. For example, the tool you use for a generative output is going to be very different than the one you use for classification or tagging.
The key to all good evals is that they need to be repeatable. If two reasonable people would disagree on whether something is clickbait per our definition, then our definition of clickbait wasn’t clear enough. With some use cases, repeatability is trivial. For example, if you’re trying to extract names from a document, you merely need to do a string comparison on the expected vs. actual output.
For other uses, especially generative outputs, repeatability is much more elusive. However, if you can break down your problem into unambiguous components you can achieve the desired repeatability.
Let’s break down each of the content types and how you can evaluate them.
- Unstructured content
Evals on unstructured content are useful for generative output and recommendation systems. Let’s consider the example of a sales bot that does cold outbound for your startup. Our goal is to make the eval repeatable and measurable.
First, we need to start by clearly defining what a “good” email consists of. In order to do this we can break down "good" into smaller parts.
- A good email is short
- A good email starts with an engaging hook
- A good email is personalized to the receiver
- A good email has a clear call to action.
Good is feeling a little less vague. There are now two things we could do.
Side-by-side evaluation
A side-by-side compares two outputs against each other and asks the rater to choose the better one. We’ve already outlined what “good” means and now we’re asking a human (or an LLM) to pick the better one based on our evaluation criteria.
The benefit of side-by-sides is that they can allow you to capture more nuance and are purely apples-to-apples. For example, a side-by-side would allow us to capture not just that a hook is engaging but between two emails, which hook is more engaging.
Score based evals
Another method to evaluate unstructured output is to give it a numerical score. In our email example, we could individually rate each of the criteria (short, engaging, personalized, call-to-action) and then combine those scores.
The benefit of score-based evals is that they can make evaluation more scientific and can be run in isolation from other models.
The hard part about creating evals for unstructured outputs is clearly defining evaluation criteria that are measurable and repeatable. Running the evaluation (either with an LLM or a human) becomes easy if the instructions are clear.
- Structured content
By structured, what I mean is content with a correct answer. Categorization, tagging, named entity recognition, classification, and extraction are all examples of structured content. Evals for structured content are generally more straightforward because the evaluation is usually just a string comparison.
Let’s consider a product categorization task. Given a product name, the goal is to categorize it into the correct product taxonomy. For example, “Bose QC35 Headphones” would be Electronics > Audio > Headphones .
The difficult part of evaluating structured content is not technically doing the evaluation, a simple string comparison works fine. The hard part is making sure that the data you’re evaluating against is correctly labeled and representative of the distribution of real-world data.
The past five projects I’ve worked on had incorrect “ground-truth” data that required fixing to properly evaluate the AI pipeline we built. You cannot trust an outsourced team to label your ground truth data for evaluation. This process is painful and tedious (no one likes data labeling) but essential to building good products.
The distribution of data matters as well. If your eval set has an overrepresentation of one type of product you will not understand how your pipeline will actually function in production. It’s fine to have your eval set oversample on “hard problems” but when you’re interpreting the results, it can be useful to weight the results based on the real-world distribution. This is especially important if you’re presenting the results to stakeholders who may not understand how you constructed the dataset.
Conclusion
The process of building with AI requires a shift from deterministic engineering to a more probabilistic, scientific approach. Central to this approach is rigorous and well-defined evaluation so you can actually measure how you’re doing and make improvements. From structured to unstructured content, a clear and repeatable evaluation methodology is key to building good AI software.
We're building LabelKit, an open-source framework to build, optimize, and evaluate AI pipelines. If you think this is interesting, give us a star on Github and share it with your friends building with AI. Feel free to dm me anytime @benscharfstein.